计算机的字长,是指针数据的位长,表明了虚拟地址空间的大小
ASCII字符构成的文件成为文本文件,其他所有文件都称为二进制文件
核心PC模型由指令集架构决定,操作围绕主存、寄存器文件、算术/逻辑单元ALU进行,进行加载、存储、操作、跳转等操作。
存储器层次结构的基本思想:上一层的存储器作为第一层存储器的高速缓存
操作系统的基本功能:1:防止硬件被失控 的应用程序滥用;2:向应用程序提供简单一致的机制来控制复杂而通常大而不同的低级硬件设备。
信息的表示和处理
信息存储
- 信息:
1 | 数值:值 小数点 符号(三要素) |
软件:
1
2
3系统软件:(用来管理整个计算机系统)
语言处理程序 操作系统 服务型程序 数据 库管理系统 网络软件计算机系统的层次结构:
| 高级语言 | 虚拟机器M3 |
|---|---|
| 汇编语言 | 虚拟机器M2 |
| 操作系统 | 虚拟机器 |
| 机器语言 | 实际机器M1 |
| 微指令语言(时间) | 微程序机器M0 |
机器数(码):原码 反码 移码 补码
数的逻辑:逻辑 算术(+ - * /) c语言中的数
逻辑运算符&&和||与对应的位级运算符&和|第二个区别:
如果对第一个参数求值就能确定表达式的结果,那么逻辑运算符就不会对第二个参数求值。例如:a&&5/a不会造成被零除,p&&*p++不会导致间接引用空指针
集合的表示与运算
- 表示:位向量表示有限集合
1 | eg:10100110 从右到左表示 该集合={1,2,5,7} |
运算:& 交集 | 并集 ^ 对称差集 ~ 补集
左移补0,但右移分为逻辑右移和算术右移,逻辑右移左端补0,算术右移左端补最高有效位的值。c语言对此没有区分,但大多数编译器对有符号数使用算术右移;无符号数右移必须是逻辑的 。Java对右移有明确的规定,x>>k表示x算术右移k个位置,x>>>k表示逻辑右移
整数表示
整数编码
有符号数:补码
B2T(X) = $-X_{w-1}2^{w-1}+\sum_{i=0}^{w-2}X_i2_i$
例:
| 10进制 | 16进制 | 2进制 | |
|---|---|---|---|
| X | 15213 | 3B 6D | 0011011 01101101 |
| Y | -15213 | C4 93 | 1100100 10010011(最高位1表示负数) |
| 原码 | 反码 | 补码 | |
|---|---|---|---|
| 11 | 0000 1011 | 0000 1011 | 0000 1011 |
| -11 | 1000 1011 | 1111 0100 | 1111 0101 |
注:负数的补码为反码加1, 正数的 原码、反码、补码都相同
知识细节
有符号数同一表示形式下,负数的表示范围 比正数的范围大1
同一位数:补码的范围不对称,|TMin|=|TMax|+1; 同一位数:最大的无符号数比有符号数的两倍多1,即:UMax = 2TMax + 1
对于大多数C语言,处理同样字长的有符号数和无符号数规则:数值可能改变,但位模式不变
eg:short v = -12345; unsigned short uv = (unsigned short) v; uv=53191 这里-12345的16位补码和53191的16位编码相同
无符号数和有符号数之间的转换规则:T–>U:补码转化为无符号数 U–>T:无符号数转化为补码
参与运算时,如果有无符号数出现在同一表达式,则有符号数强制转化为无符号数
扩展一个数字的位表示:无符号数零扩展,补码数(有符号数)符号扩展
截断无符号数:丢弃高位取地位; 截断有符号数:截断后将最高位转化为符号位
整数运算
有符号数和无符号数转换的基本原则:
1 | -位模式不变 |
加法: 无/有符号数的加法:正常加法后再截断,位级的运算相同
无符号数:加后对$2^w$求模
符号位扩展
1 | -无符号数:填充0 |
截断
1 | -无论有无符号数,多出的位数都被截断 |
-对于小整数,结果是明确的预期值
检测无符号数加法中的溢出:
s =x+y,当且仅当s < x(或等价的s < y)时发生了溢出
无符号数逆元(求反):x=0时:-x=0
x > 0时: -x = $2^w$
补码加法:
对于-$2^{w-1}\le,y\le2^{w-1}$-1的整数x和y,有
$$
\begin{equation}x+^t_wy=\begin{cases}x+y-2^w& 2^{w-1}\le{x+y} & 正溢出\x+y & -2^{w-1}\le{x+y}<2^{w-1} & 正常\x+y+2^w & x+y<-2^{w-1} & 负溢出\end{cases}\end{equation}
$$
对于满足TMi$n_w\le$x,y$\le$TMax$_w$的和y,令s=x+y,当且仅当x > 0,y > 0但s$\le$0时发生了正溢出;当且仅当x < 0,y < 0但s$\geq$0时发生了正溢出
补码的非
对满足$TMin_w\le x\le TMax_w$ 的$x$,其补码的非$-^t_wx$由下式给出:
$$
\begin{equation}-^t_wx=\begin{cases}TMin_w& x = TMin_w\-x & x>TMin_w\end{cases}\end{equation}
$$
也就是说,对w位的补码加法来说,$TMin_w$是自己的加法的逆,而对其他的都有$-x$作为其加法的逆
补码非的位级表示
方法一:对每一位求补,再对结果加1
方法二:找到最右边的第一个1的位置,然后将该位置左边的所有为取反
浮点数
- IEEE标准:

- 浮点数规格化的值(frac、exp)

对于非规格化值:E=1-Bisas,M=f,不包括隐含的开头的1
舍入

将float或double转化成int,值将向零舍入
程序的机器级表示
数据格式
c数据类型的宽度
| c数据类型 | 32位 | 64位 | x86-64 |
|---|---|---|---|
| char | 1 | 1 | 1 |
| short | 2 | 2 | 2 |
| int | 4 | 4 | 4 |
| long | 4 | 8 | 8 |
| float | 4 | 4 | 4 |
| double | 8 | 8 | 8 |
| long double | - | - | 10/16 |
| pointer | 4 | 8 | 8 |
访问信息
常规的movq指令只能以表示为32位补码数字的立即数作为源操作数,然后把这个值符号扩展到64位的值放大目的位置;
MOVZ类中的指令把目的中剩余的字节填充为0,而MOVS类中的指令通过符号扩展来填充,把源操作数的最高位进行复制。
MOVZ类(零扩展)的指令:以寄存器或地址内存作为源,以寄存器作为目的;
MOVS类(符号扩展)的指令:以寄存器或地址内存作为源,以寄存器作为目的;cltq指令无操作数:只作用于%eax和%rax
算术和逻辑操作
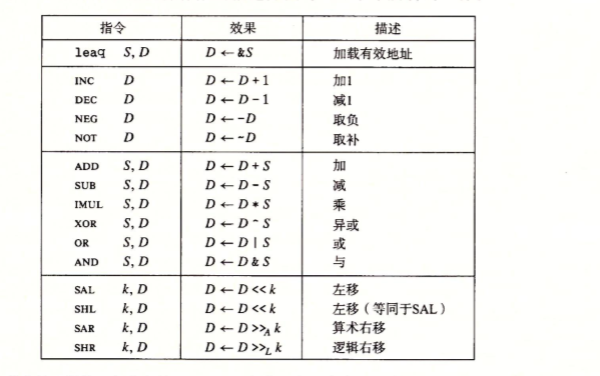
(1)leap指令目的操作数必须是寄存器
(2)左移指令有两个:SAL和SHL,两者效果一样,都是右边补0;右移指令不同,SAR执行算术移位,补充符号位,而SHR执行逻辑移位,补充0
(3)特殊的算术操作

有符号除法指令 idivl 将%rdx高64位和%rax低64位中的128位作为被除数,而除数作为指令的操作数给出。指令将商存储在%rax,余数存储在%rdx
cqto指令可以不需要操作数,隐含读出%rax的符号位并将其复制到%rdx的每一位
控制
(1)leaq指令不改变条件码
(2)CMP指令和TEST指令只改变条件码,前者基于sub,后者基于and
(3)条件码通常不会直接读取,常用使用方法:
a、根据条件码的某种组合将一个字节设置为0或1(即set指令)
b、条件跳转到程序的某个其他部分
c、有条件的传送数据
(4)set指令:

过程
(1)传递控制、传递数据、分配和释放内存
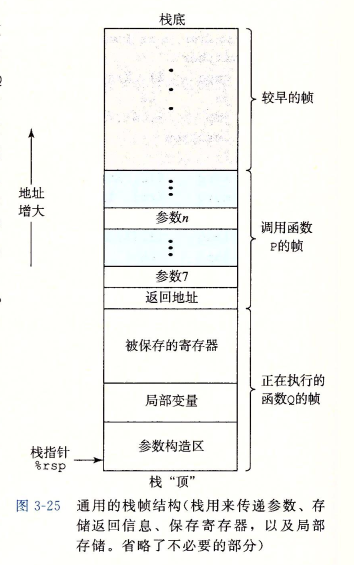
(2)调用函数前,把所有的参数都先存储,包括形参,存储完毕才开始调用函数
(3)栈上的局部变量(局部数据必须用主存的情况)
1)寄存器不足够存放所有的本地数据
2)对一个局部变量使用取址符&,因此必须为其产生一个地址
3)某些局部变量是数组或结构,因此必须通过数组或结构引用访问到。
注:寄存器是唯一被所有过程共享的资源
对抗缓冲区溢出
方法:1、栈随机化 ;2、栈破坏检测 ;3、限制可执行代码区域
过程中的浮点代码
XMM寄存器8xmn0~ 8xmm7最多可以传递8个浮点参数。按照参数列出的顺序使用这些寄存器。可以通过栈传递额外的浮点参数。
函数使用寄存器%xmm0来返回浮点值。
所有的XMM寄存器都是调用者保存的。被调用者可以不用保存就覆盖这些寄存器
中任意一个。| 单精度 | 双精度 | 效果 | 描述 |
| —— | —— | —— | ———————– |
| vxorps | vorpd | D<-x*y | 位级异或(EXCLUSIVE-OR) |
| vandps | andpd | D<-x&y | 位级与(AND) |
| 指令 | 基于 | 描述 |
|---|---|---|
| ucomiss x,y | y-x | 比较单精度值 |
| ucomisd x,y | y-x | 比较双精度值 |
处理器体系结构
1、程序计数器PC保存当前正在执行指令的地址
2、内存从概念上来说就是一个很大的字节数组,保存着程序和数据。Y86-64程序用虚拟地址来引用内存位置。硬件和操作系统软件联合起来将虚拟地址翻译成实际或物理地址
3、Y86-64每条指令需要1~10个字节不等,每条指令的第一个字节表明指令的类型,这个字节分为两部分,每部分4位:高四位是代码部分,低四位是指令部分。功能值只有在一组相关指令共用一个代码时才有用。
4、指令集的一个重要性质就是每个字节编码必须有唯一的解释
5、时钟寄存器:存储单个字:PC、条件代码和程序状态Stat 随机访问存储器:存储多个字
6、指令处理:
取指、译码、执行、访存、写回、更新PC
7、SEQ的实现包括组合逻辑和两种存储设备:时钟寄存器和随机访问寄存器。四个硬件单元对时序控制:程序计数器、条件码寄存器、数据内存和寄存器文件,通过时钟信号控制。
8、组织原则:从不读回,即处理器从来不需要为了完成一条指令的执行而去读由该指令更新了的状态。
9、每个周期开始前,状态单元(PC、条件码、数据内存、寄存器文件)是根据前一条指令设置的。信号传播通过组合逻辑,创建出新的状态单元的值。
优化程序性能
程序性能标准:每元素的周期数CPE
优化方法:
1、消除循环低效率:代码移动:
2、减少过程调用
3、消除不必要的内存引用
4、循环展开:减少迭代次数
5、提高并行性:多个累计变量并行求、重新结合变换
课本总结:
1)高级设计:算法和数据结构
2)基本编码原则:
消除连续的函数调用:将计算移动到循环外
消除不必要的内存引用:引用临时变量保存中间结果,最后结果得出才放入数组或全局变量
3)低级优化:
展开循环,降低开销,并且使进一步优化成为可能
通过使用例如多个累积变量和重新结合等技术,提高指令集并行
用功能性的风格重写条件操作,使得编译采用条件数据传送
限制因素:
1、寄存器溢出
2、分支预测错误和预测错误处罚:不过分关心可预测的分支、书写适合条件传送的代码
存储器层次结构
存储技术
随机访问存储器
随机访问存储器分(RAM)为两类:静态SRAM(更快)和动态DRAM
(1)静态(SRAM)
SRAM将每个位存储在一个双稳态的存储器单元,每个单元由一个六晶体管电路实现,可无限期保持在两个不同的电压配置或状态之一
(2)动态(DRAM)
DRAM将每个位存储为对一个电容的充电,对干扰敏感且不能恢复
对比:

(3)传统的DRAM
DRAM芯片中的单元(位)被分成d个超单元,每个超单元由w个DRAM单元组成,一个d*w的DRAM存储了dw位信息。超单元被组织成r行c列的矩阵,rc=d。
每个超单元存储一个字节
(4)内存模块
–DRAM芯片封装在内存模块中,插到主板的扩展槽上
–内存地址A取值过程:

(5)增强的DRAM
快页模式DRAM、扩展数据输出DRAM、同步DRAM、双倍数据速率同步DRAM、视频RAM
(6)非易失性存储器
ROM
(7)访问主存
总线:能够携带地址、数据和控制信号,分为:系统总线和内存总线
磁盘存储
磁盘读取时间计算:

局部性
(1)重复引用相同局部变量的程序具有良好的时间局部性
(2)步长越小,空间局部性越好
(3)对于取值指令,循环具有良好的时间和空间局部性,循环体越小,循环迭代次数越多,局部性越好
存储器层次结构
存储器层次结构
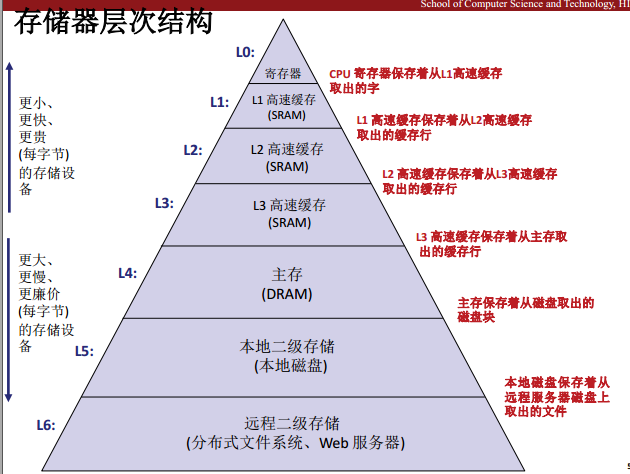
高速缓存存储器
缓存不命中:
冷不命中(强制性不命中):
k层缓存有空行,程序最开始运行时均为冷不命中
冲突不命中
k层中没有空行
容量不命中
组相连高速缓存、组相连高速缓存、全相连高速缓存
编写高速缓存存储器
写命中:
直写:高速缓存中更新的数据立即写回到低一层中
写回:尽可能推迟更新,当替换算法要驱逐这个更新过的块时,才把它写到紧接着的低一层中
写不命中:
写分配:加载相应的低一层的块到高速缓存中,然后更新这个高速缓存块
非写分配:避开高速缓存,直接把这个字写到低一层中
**直写高速缓存通常时写分配的,写回高速缓存通常是非写分配的
综合:高速缓存对程序性能的影响
如果一个高速缓存的块大小为B字节,那么一个步长为k(字)的引用模式平均每次循环迭代会有min(1,(wordsize*k)/k))次缓存不命中
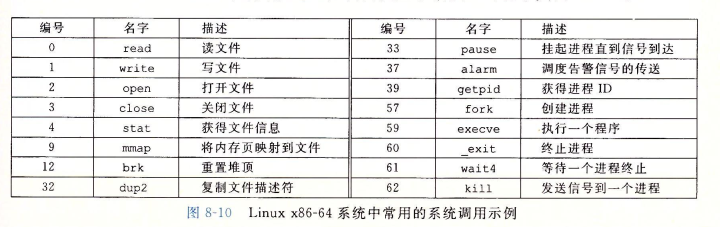
异常控制流
异常
(1)异常是控制流中的突变,用来响应处理器状态中的变化。是异常控制流的一种形式,一部分由硬件实现,一部分由操作系统实现
(2)事件处理:

(3)异常分类

进程
进程:一个执行中程序的实例。系统中每个程序都运行在某个进程的上下文中。上下文是由程序正确运行所需的状态组成
进程提供的关键抽象:
一个独立的逻辑控制流、一个私有的地址空间
并发流:一个逻辑流的执行在时间上与另一个流重叠,称为并发流,这两个流被称为并发的运行。多个流并发地执行一般现象被称为并发。一个进程和其他进程轮流运行的概念称为多任务。一个进程执行它的控制流的一部分的每一时间段叫做时间片,因此,多任务也叫时间分片。
如果两个流并发的运行在不同的处理器核或计算机上,那么我们称它们为并行流,它们并行地运行,且并行地执行
进程地址空间
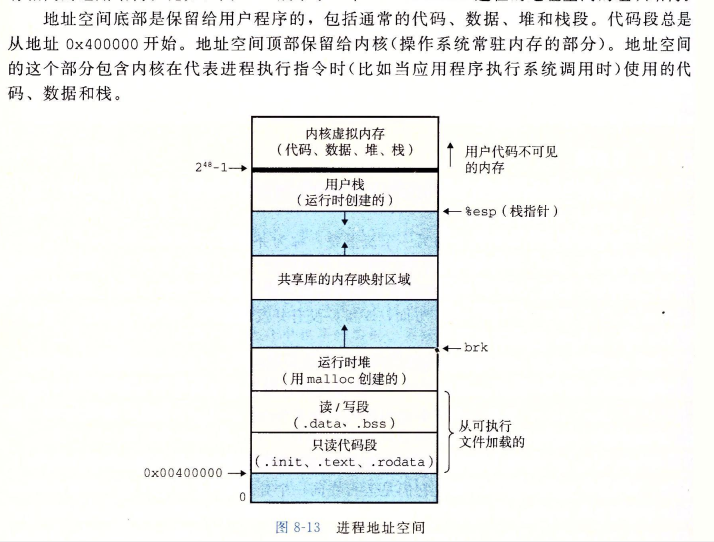
用户模式和内核模式:进程从用户模式切换到内核模式的唯一方式是异常
上下文切换:
1)保存当前进程的上下文; 2)恢复某个先前被抢占的进程被保存的上下文; 3)将控制传递给这个新恢复的进程
进程控制
- 进程的三种状态:
运行:进程要么被执行,要么等待被执行且被内核调度
停止:进程的执行被挂起,且不会被调度。当收到SIGSTOP 、SIGTSTP、SIGTTIN、SIGTOUT信号时,进程停止,并且保持到收到SIGCOUT信号
终止:1)收到一个信号,该信号的默认行为是终止;2)从主程序返回;3)调用exit函数
- 父进程和子进程最大的区别是PID不同。
fork被调用一次,返回两次。一次是在父进程中,fork返回子进程的PID,一次是在新建的子进程中,返回0;
子进程和父进程:
1)fork函数调用一次,返回两次;2)子进程和父进程并发运行;3)相同但是独立的地址空间;4)共享文件
pid_t wait_pid(int *statusp) : 如果成功,返回子进程的PID;如果WNOHANG,返回0;如果其他错误,返回-1
unsigned int sleep(unsigned int secs):返回还要休眠的秒数
int pause(void):总是返回-1,让函数休眠,直到该进程接收到另一个信号
execve:在当前进程的上下文中加载并运行一个新程序,从不返回,(如果找不到filename,才会返回到调用程序)。
编写信号处理程序
1、安全的信号处理
(1)处理程序要尽可能的简单
(2)在处理程序中只调用异步信号安全的函数
(3)保存和恢复errno
(4)阻塞所有信号,保护对共享数据结构的访问
(5)用volatile声明全局变量
(6)用sig_atomic_t声明标志
2、正确的信号处理:未处理的信号不排队
3、可移植的信号处理
由于本人有一丢丢懒~,漏掉的一些内容懒得更新,排版也只是凑合,还请大家原谅啦啦—–